經濟部 iPAS AI應用規劃師初級能力鑑定-考試樣題
科目一:人工智慧基礎概論
A
(A) AI系統的開發者對AI系統的行為負責
(B) AI系統的使用者對AI系統的結果負責
(C) AI系統本身對其行為負責
(D) 政府對AI系統的發展負責
A
(A) 生成式AI通過分析大量數據來生成新數據,模擬數據分佈以創造 與訓練數據相似的結果
(B) 生成式AI主要通過預定義的規則來進行數據處理和分類
(C) 生成式AI專注於數據分類和迴歸預測,幫助識別已知數據中的模 式
(D) 生成式AI通過自動化的方式清洗數據,提升數據分析的準確性
A
何者並非 以
為主要設計目的?
(A) 支援向量機(Support Vector Machine)
(B) 變分自編碼器(Variational Autoencoder)
(C) 自迴歸模型(Autoregressive Model)
(D) 擴散模型(Diffusion Model)
B.
造成資料結構重複與使用混淆,此種情形屬於下列哪一種資料 品質問題?
(A) 重複資料(Duplicate Data)
(B) 冗餘資料(Redundant Data)
(C) 格式錯誤資料(Malformed Data)
(D) 缺失資料(Missing Data)
B.
若模型使 用的輸入資料包含「商品售價」、「顧客年齡」、「運送天數」,
而模型的輸 出為是否退貨(是/否)。
請問在此模型中,「是否退貨」應歸類為下列哪 一類變數?
(A) 特徵(Feature)
(B) 標籤(Label / Target)
(C) 超參數(Hyperparameter)
(D) 正則化係數(Regularization Coefficient)
支援向量機(Support Vector Machine, SVM)
是一種監督式學習的方法 , 一般是應用於分類
(Classification/supervised learning)等相關議題上。
SVM 基本運作模式如下:
在給定一群訓練樣本之下,每個樣本會分別對應至
兩個不同的類別(Category),
SVM 會嘗試從建構一個模型(Model),
並利用此模型將每一個樣本分配到一個類別上。
Support Vector Machine(簡稱SVM)模型
中文全稱為 支援向量機 ,
是一種基於統計原理的機器學習演算法,
應運用 資料分類(Classifier)以及迴歸(Regressor)
2017 Yeh James
支援向量機(Support Vector Machine) 簡稱SVM這個名字光看字面三個字的意思都懂,但合起來就完全看不懂了。不過SVM概念很簡單,先聽我說個故事
有一天上帝給了你一個考驗,要你用一個棍子將這兩顆不同顏色的球分開
於是你使用方法
順利找個一個放棍子的方法將這兩種不同顏色的球分開,
於是上帝又創造一些球出來,你發現原先棍子擺放位子很容易造成未來產生的球的分類錯誤
因此你發現應該要將棍子調整成這樣才能夠在更準確分類在未來產生的球(這就是SVM最主要的核心概念)
上帝發現你已經成長了不少了,簡單的問題難不了你,因此又出一道考題給你,要如何正確分類以下的球
觀察一下後你發現紅球、藍球的質量不太一樣,這時你靈機一動,深呼吸一口氣,將你的查克拉聚集在手上,大力一拍桌子,讓這些球飛到空中,你再拿一張白紙將將些球分開
從正上方的視角來看這藍球跟紅球就像是被一條虛擬的線分開了
常見的自編碼器種類:
稀疏自編碼器(Sparse Autoencoder): 透過限制隱藏層單元的活性,使模型學習到更加有用的特徵表示,同時實現特徵的稀疏性。去噪自編碼器(Denoising Autoencoder): 用於去除數據中的雜訊,訓練時將加入雜訊的數據作為輸入,要求模型重構出原始數據。變分自編碼器(Variational Autoencoder,VAE) : 引入了機率和隨機性的自編碼器,能夠生成連續潛在空間中的新樣本,並且 用於生成模型。
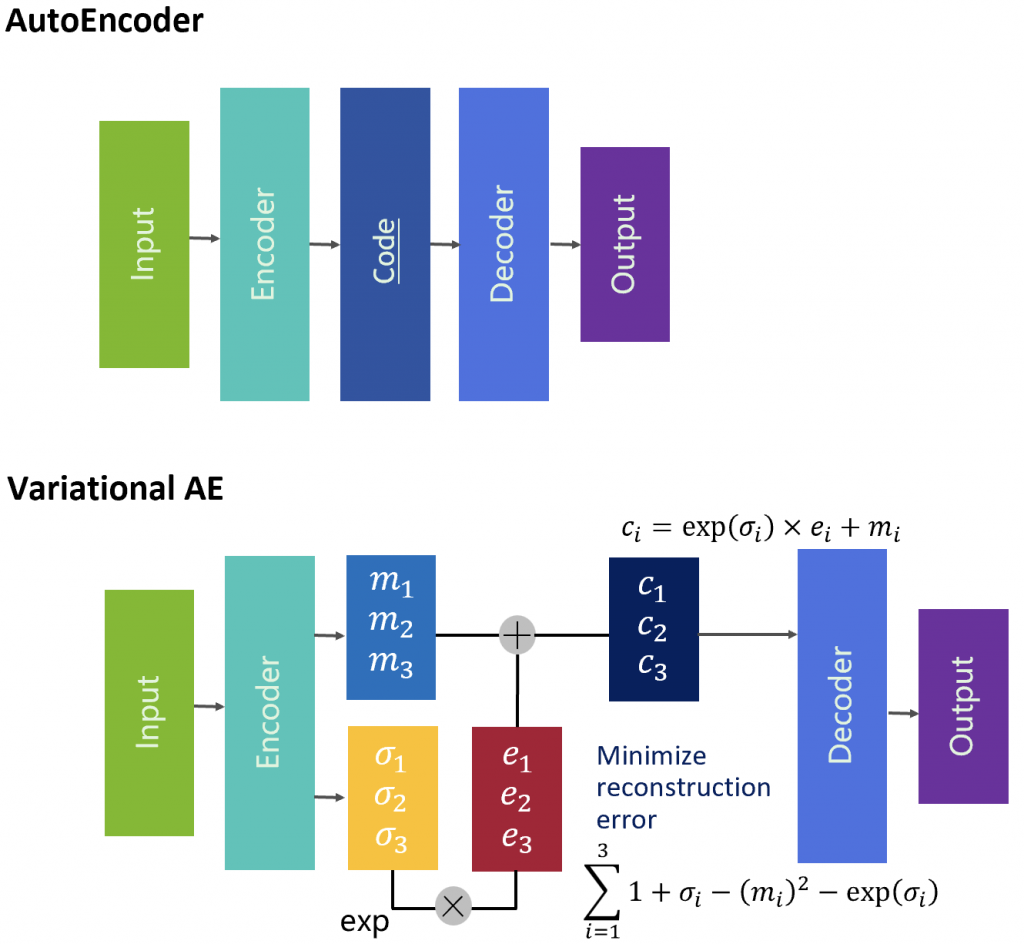
變分自編碼器(Variational Autoencoder,VAE)
是一種生成模型, 結合了自編碼器和機率建模的概念 ,用於學習數據的低維度表示並生成新的樣本。以下是有關變分自編碼器的簡要介紹:
自編碼器結構: VAE由兩個主要組件組成: 編碼器(Encoder)和解碼器(Decoder)。 編碼器將輸入數據映射到均值和變異數參數,解碼器使用這些參數來生成新的樣本。 隨機性和潛在變數: VAE引入了潛在變數(Latent Variable) ,透過這些變數引入了隨機性。編碼器學習如何將輸入數據映射到潛在變數的分佈,解碼器則從潛在變數的分佈中生成樣本。 生成過程: 在生成過程中,從潛在變數的分佈中抽樣,然後使用解碼器生成相應的樣本。這種過程使得VAE能夠生成具有隨機性的多樣化樣本。損失函數: VAE的訓練使用的是一種特殊的損失函數,即「重建損失」和「KL 散度(Kullback-Leibler divergence)」的組合,又稱為ELBO。重建損失衡量生成樣本的質量,而KL 散度則衡量潛在變數的分佈與標準正態分佈之間的差異。 生成新樣本: VAE訓練完成後,可以使用解碼器從潛在變數的分佈中抽樣,生成新的樣本。 由於潛在變數的隨機性,生成的樣本通常呈現出多樣性。 應用範疇: VAE 在生成圖像、音頻、文本 等多種類型的數據上都有應用。它可以生成高質量、多樣性的樣本,並且在許多生成任務中取得了優異的成果。
總之,變分自編碼器(VAE)是一種結合自編碼器和機率建模的生成模型,透過引入潛在變數和隨機性,能夠生成多樣性的樣本。 VAE在生成和潛在變數建模方面的特點,使其成為生成模型領域的重要成員。
2023 Nick
變分自編碼器與自編碼器的差別,參考下圖。
自回歸(autoregressive)模型
是一種在機器學習和統計學中常用的方法 , 主要用來處理序列數據的預測 。 它的基本概念是:序列中的當前值是過去值的函數, 藉由利用序列中先前的數據點來預測下一個數據點。
具體來說,自回歸模型 會根據時間序列中前面一段時間(稱為滯後期數) 的觀測值, 透過線性組合與隨機誤差 來估計當前的數值。
擴散模型(Diffusion Model)
是一種 基於機率 的 生成式AI技術 ,主要用於 圖像生成、修復及語音合成 。
其核心原理是 模擬非平衡態熱力學 ,透過 「前向過程」
逐步對數據 添加高斯雜訊 直到 變成純雜訊 , 再透過
神經網路學習「逆向過程」去噪 ,從而從隨機噪聲中生成逼真數據。
相比GANs,它訓練更穩定 , 是Stable Diffusion和DALL-E 2的核心技術。
關鍵概念與運作流程
前向過程 (Forward Process/Diffusion):
將真實數據(如圖像)逐步加入隨機高斯雜訊,
直到最終成為完全無序的雜訊。
逆向過程 (Reverse Process/Denoising):
這是模型的訓練目標。
神經網路被訓練來「反轉」前向過程 ,將一張純雜訊圖像逐步去噪,
還原成高質量的真實圖像。
生成機制:
訓練完成後, 模型可以從一個完全隨機的噪聲分佈開始,
逐步生成新的、獨特的數據。
技術優勢與應用
訓練穩定性: 不像GAN(生成對抗網路)需要同時訓練產生器與判別器,
擴散模型訓練更加穩定,
不容易出現模式崩潰(Mode Collapse)。
高品質生成: 能生成多樣化、高解析度的圖像。
廣泛應用: 應用於
1.圖像修復(Inpainting)、
2.超解析度成像(Super-resolution)、
3.文生圖(Text-to-Image)、
4.影像生成影片 等。











.jpg)


















